Acwing蓝桥杯辅导课之数论
等差数列
题目
原题链接数学老师给小明出了一道等差数列求和的题目。
但是粗心的小明忘记了一部分的数列,只记得其中 N 个整数。
现在给出这 N 个整数,小明想知道包含这 N 个整数的最短的等差数列有几项?
输入格式
输入的第一行包含一个整数 N。
第二行包含 N 个整数 A1,A2,⋅⋅⋅,AN。(注意 A1∼AN 并不一定是按等差数
列中的顺序给出)
输出格式
输出一个整数表示答案。
数据范围
2 ≤ N ≤ 100000,
0 ≤ Ai ≤ 10^9
输入样例:1
25
2 6 4 10 20
输出样例:1
10
样例解释
包含 2、6、4、10、20 的最短的等差数列是 2、4、6、8、10、12、14、16、18、20。
分析
这题一般能想到将题意转化为求几个可能公差之间的最大公约数。所以只要会求最大公约数,这题就迎刃而解。
代码
1 |
|
最大公约数(gcd)模板1
2
3
4LL gcd(LL a,LL b)
{
return b ? gcd(b,a % b) : a;
}
X的因子链
题目
原题链接输入正整数 X,求 X 的大于 1 的因子组成的满足任意前一项都能整除后一项的严格递增序列的最大长度,以及满足最大长度的序列的个数。
输入格式
输入包含多组数据,每组数据占一行,包含一个正整数表示 X。
输出格式
对于每组数据,输出序列的最大长度以及满足最大长度的序列的个数。
每个结果占一行。
数据范围
1 ≤ X ≤ 220
输入样例:1
2
3
4
52
3
4
10
100
输出样例:1
2
3
4
51 1
1 1
2 1
2 2
4 6
分析
这题题意比较绕,实际问的就是一个数的所有质因数组成的序列的最大长度,以及序列个数,其中序列后一个数必须是前一个数的倍数,且严格递增。本质上是一道组合问题,是基于算术基本定理的。假定我们知道这个数的所有质因数有哪些,以及它们的次数,那么最大长度应该是所有次数之和,而序列个数则是这些次数的组合。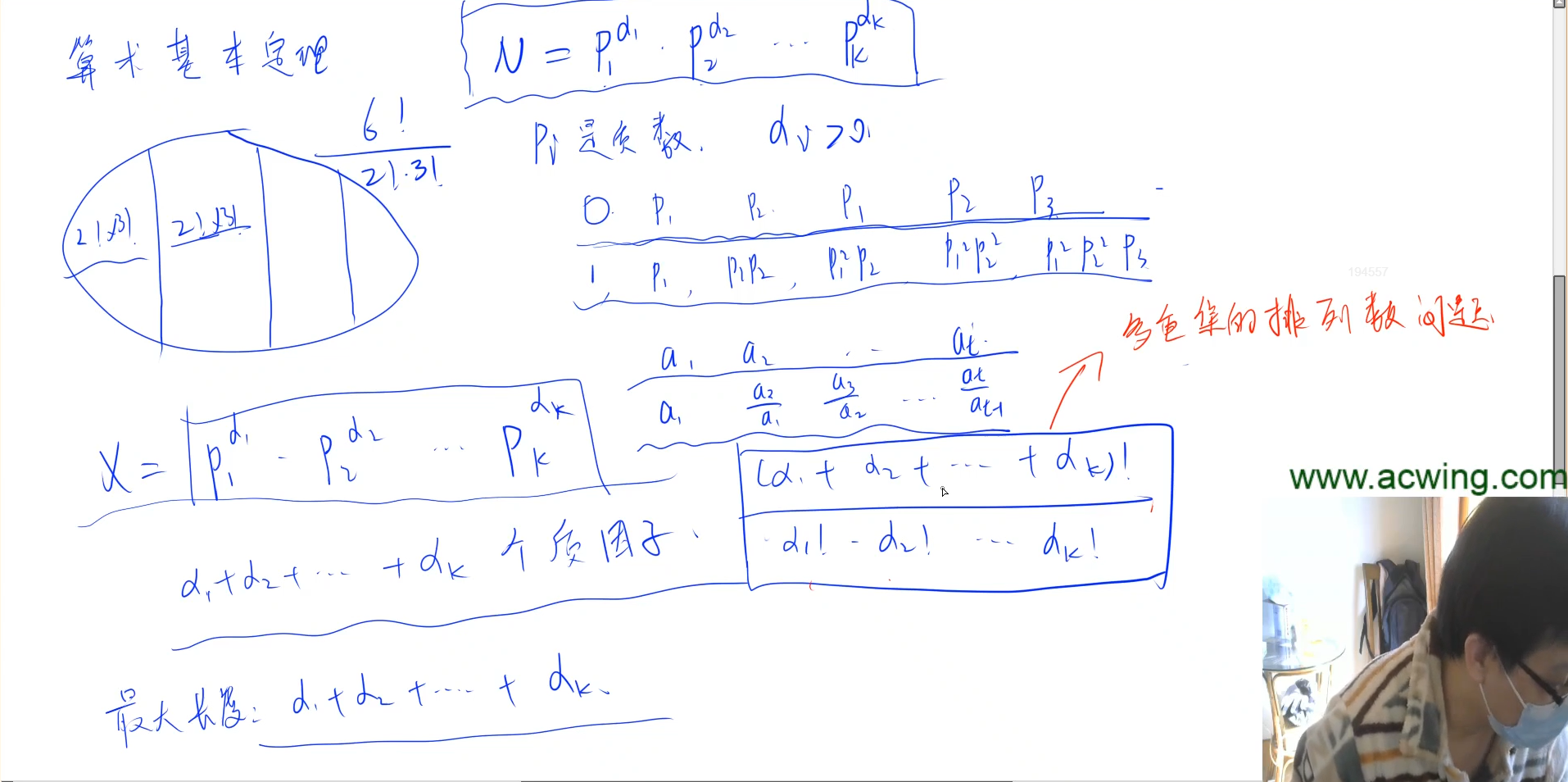
图中y总介绍了算术基本定理是什么,以及对于次数的组合的解释。
代码
1 |
|
线性筛模板1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24//线性筛
int primes[N],cnt;
bool st[N];
//记录每个合数的最小质因数
int minp[N];
void get_primes(int n)
{
for(int i = 2;i <= n;i++)
{
if(!st[i])
{
//质数是它自己
minp[i] = i;
primes[cnt++] = i;
}
for(int j = 0;primes[j] * i <= n;j++)
{
st[primes[j] * i] = true;
minp[primes[j] * i] = primes[j];
if(i % primes[j] == 0) break;
}
}
}
聪明的燕姿
题目
原题链接城市中人们总是拿着号码牌,不停寻找,不断匹配,可是谁也不知道自己等的那个人是谁。
可是燕姿不一样,燕姿知道自己等的人是谁,因为燕姿数学学得好!
燕姿发现了一个神奇的算法:假设自己的号码牌上写着数字 S,那么自己等的人手上的号码牌数字的所有正约数之和必定等于 S。
所以燕姿总是拿着号码牌在地铁和人海找数字(喂!这样真的靠谱吗)。
可是她忙着唱《绿光》,想拜托你写一个程序能够快速地找到所有自己等的人。
输入格式
输入包含 k 组数据。
对于每组数据,输入包含一个号码牌 S。
输出格式
对于每组数据,输出有两行。
第一行包含一个整数 m,表示有 m 个等的人。
第二行包含相应的 m 个数,表示所有等的人的号码牌。
注意:你输出的号码牌必须按照升序排列。
数据范围
1 ≤ k ≤ 100,
1 ≤ S ≤ 2×10^9
输入样例:1
42
输出样例:1
23
20 26 41
分析
这题的难点在于dfs剪枝和顺序的设计,如果直接dfs的话,第一个超时的点是判断质数,第二个超时点是枚举所有质数。
优化判断质数的过程可以用线性筛预处理,根据对约数之和的分析,实际上只需要枚举到根号S即可,这一步就是剪枝。
约数之和
剪枝证明
图中y总讲解了约数之和如何通过质因数表示,以及为什么只需要枚举到根号S。
代码
1 |
|
五指山
题目
原题链接大圣在佛祖的手掌中。
我们假设佛祖的手掌是一个圆圈,圆圈的长为 n,逆时针记为:0,1,2,…,n−1,而大圣每次飞的距离为 d。
现在大圣所在的位置记为 x,而大圣想去的地方在 y。
要你告诉大圣至少要飞多少次才能到达目的地。
注意:孙悟空的筋斗云只沿着逆时针方向翻。
输入格式
有多组测试数据。
第一行是一个正整数 T,表示测试数据的组数;
每组测试数据包括一行,四个非负整数,分别为如来手掌圆圈的长度 n,筋斗所能飞的距离 d,大圣的初始位置 x 和大圣想去的地方 y。
输出格式
对于每组测试数据,输出一行,给出大圣最少要翻多少个筋斗云才能到达目的地。
如果无论翻多少个筋斗云也不能到达,输出 Impossible。
数据范围
1 ≤ T ≤ 5,
2 < n < 10^9,
0 < d < n,
0 ≤ x,y < n
输入样例:1
2
32
3 2 0 2
3 2 0 1
输出样例:1
21
2
分析
将题意转化后我们可以发现,实际上就是解一个线性同余方程,即ad - bn = y - x,其中a和b为系数。
所以可以想到用扩展欧几里得算法求解。
代码
1 |
|
扩展欧几里得(exgcd)模板1
2
3
4
5
6
7
8
9
10
11LL exgcd(LL a,LL b,LL & x,LL & y)
{
if(!b)
{
x = 1,y = 0;
return a;
}
LL d = exgcd(b,a % b,y,x);
y -= a / b * x;
return d;
}
 wechat
wechat- alipay


